Rows: 2798 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (6): Owner, Team, League, Recipient, Amount, Party
dbl (1): Election Year
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
skim(donation)
Data summary
Name
donation
Number of rows
2798
Number of columns
7
_______________________
Column type frequency:
character
6
numeric
1
________________________
Group variables
None
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
Owner
0
1
9
43
0
158
0
Team
0
1
9
59
0
115
0
League
0
1
3
14
0
16
0
Recipient
0
1
3
96
0
1274
0
Amount
0
1
3
10
0
244
0
Party
0
1
3
33
0
7
0
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
Election Year
0
1
2017.93
1.6
2016
2016
2018
2020
2020
▇▁▇▁▇
Clean and wrangle data
These are the following steps I took to prepare the data.
Filter for rows containing only the 6 leagues, leaving out ones that were cross-listed among many leagues. This removed a large amount of the data, meaning that a majority of team owners own multiple teams across various leagues.
Filter for rows containing only democrat or republican, leaving out bipartisan donations. I would have left these in but I had issuing renaming all variations to just bipartisan.
Parse the numerical values from Amount so it can then act as a numerical.
Group by League, Election Year, and Party
Sum the Amount of each group to find the total dollar amount of donations from each of the 6 leagues to each of the two parties in a given year.
Warning: There was 1 warning in `filter()`.
ℹ In argument: `League == c("MLB", "NASCAR", "NBA", "NFL", "NHL", "WNBA")`.
Caused by warning in `League == c("MLB", "NASCAR", "NBA", "NFL", "NHL", "WNBA")`:
! longer object length is not a multiple of shorter object length
Warning: There was 1 warning in `filter()`.
ℹ In argument: `Party == c("Democrat", "Republican")`.
Caused by warning in `Party == c("Democrat", "Republican")`:
! longer object length is not a multiple of shorter object length
`summarise()` has grouped output by 'League', 'Election Year'. You can override
using the `.groups` argument.
skim(donation_clean)
Data summary
Name
donation_clean
Number of rows
32
Number of columns
4
_______________________
Column type frequency:
character
2
numeric
2
________________________
Group variables
None
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
League
0
1
3
6
0
6
0
Party
0
1
8
10
0
2
0
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
Election Year
0
1
2018.0
1.68
2016
2016
2018
2020
2020
▇▁▇▁▇
party_donations
0
1
138422.2
379996.99
1600
9250
18450
65300
1808600
▇▁▁▁▁
Plot data
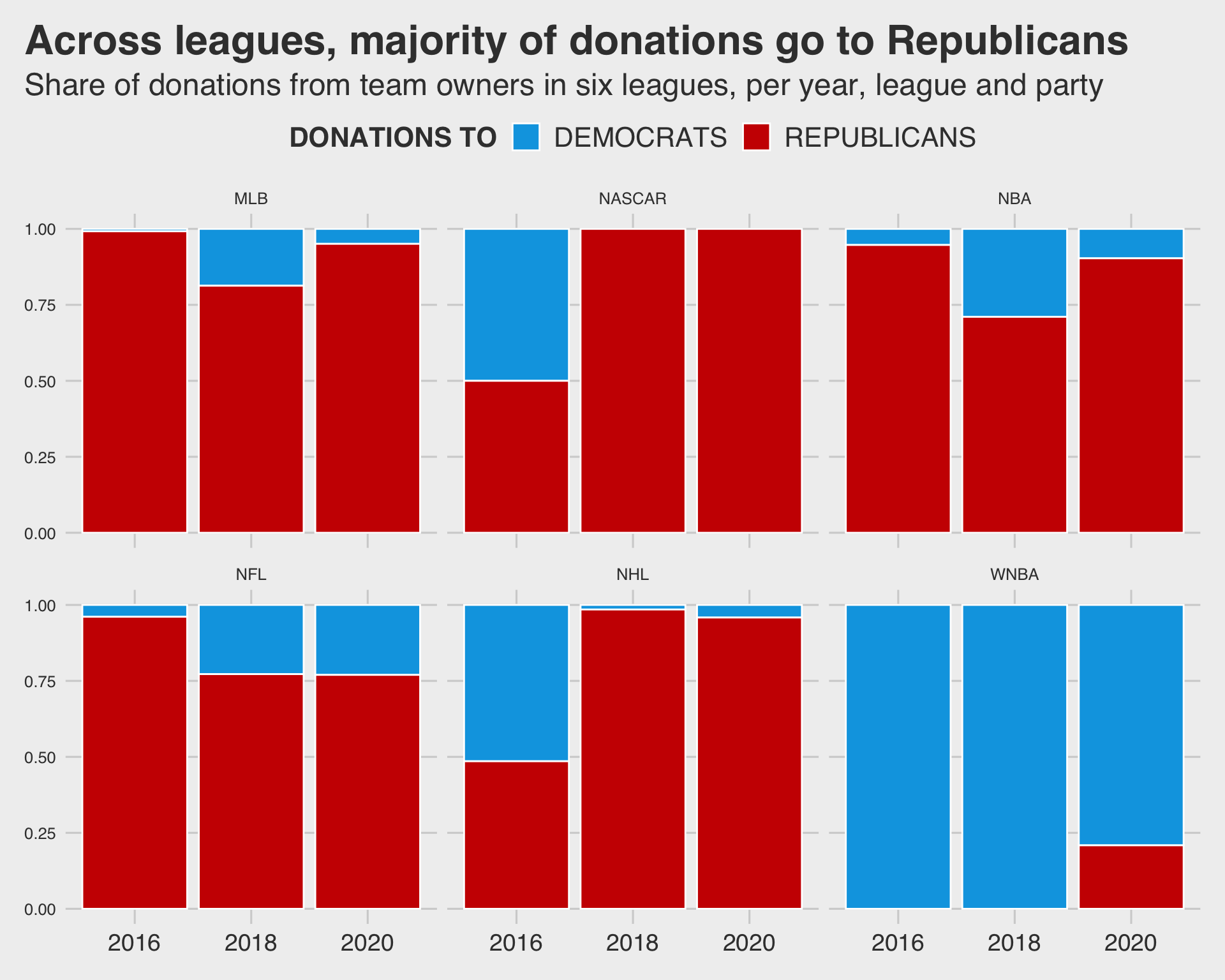
donation_plot <- donation_clean %>%ggplot(aes(fill=Party, y=party_donations, x=`Election Year`)) +geom_bar(position ="fill", stat ="identity", color ="white") +#basic geometry of plot, bar plotfacet_wrap(as.factor(donation_clean$League)) +#plot by individual Leaguescale_fill_manual(name="DONATIONS TO", values=c("#00A5E3", "#CC0000"), #looked up hexcodes on google labels=c("DEMOCRATS","REPUBLICANS")) +#fill colors in correct ordertheme_fivethirtyeight() +#theme from fivethirtyeight websitescale_x_continuous(breaks =seq(2016,2020,2)) +#2 year breaks between 2016 & 2020labs(title ="Across leagues, majority of donations go to Republicans",subtitle ="Share of donations from team owners in six leagues, per year, league and party") +theme(legend.title =element_text(face ="bold", size =16),legend.text =element_text(size =16),plot.title.position ="plot",plot.title =element_text(face ="bold", size =24),plot.subtitle =element_text(size =18),legend.position ="top",axis.text.x =element_text(size =14)) donation_plot
You will notice that the proportions on my plot are slightly different from the original. This is because I excluded all cross-listed league affiliations (for the sake of time, but in the future I would like to be able to parse these out into individual observations). I also excluded bipartisan donations and NAs because I was having trouble renaming these all to bipartisan. I would also like to work on this, as I would like to be able to re-create this chart more accurately.
I also had some formatting issues that I couldn’t quite work out on my own. For one, I could not figure out how to change the size of the facet labels. I also struggled to find a way to change the y-axis tick labels to be percentages like on the original.